
MESCLAGEM DE DADOS COM APACHE HOP
- Luiz Henrique de Oliveira Bueno
- 29 de set. de 2024
- 4 min de leitura
Atualizado: 3 de out. de 2024

Introdução:mini projeto Apache Hop Merge Test e INNER JOIN de tabelas.
O que é MERGE no banco de dados?
A instrução MERGE realiza operações de inserção, atualização ou exclusão em uma tabela de destino usando os resultados de uma junção com uma tabela de origem. Por exemplo, sincronize duas tabelas inserindo, atualizando ou excluindo linhas em uma tabela com base nas diferenças encontradas na outra tabela.
CONCEITOS FUNDAMENTAIS
Antes de nos aprofundarmos, vamos dedicar um minuto para nos familiarizar com o jargão Hop.
Metadados são de longe o conceito mais importante em todo o Hop. Cada item que abordaremos abaixo é definido como metadados. Todas as interações entre o Hop e outros componentes na sua arquitetura de dados são feitas por meio de metadados. Metadados são o cerne de tudo no Hop .
Pipelines são coleções de transforms , conectadas por hops . Todas as transforms em um pipeline rodam em paralelo.
Workflows são coleções de ações , conectadas por hops . Todas as ações em um workflow são executadas sequencialmente por padrão.
Projetos são coleções lógicas de código de hop e configuração. Ambientes contêm metadados específicos do ambiente (por exemplo, dev, uat, prd).
TIPOS DE ITENS
ACTION
Uma Ação é uma operação realizada em um Fluxo de Trabalho. Ações são executadas sequencialmente por padrão, com execução paralela como uma opção de configuração. Uma Ação retorna um código de saída verdadeiro ou falso, que pode ser usado (ou ignorado) na execução do Fluxo de Trabalho.
HOP
Um Hop vincula Ações em um Workflow ou Transformações em um Pipeline. Em Workflows, Hops operam com base no status de saída de Ações anteriores, Hops em Pipelines passam dados entre Transformações.
PIPELINE
Os pipelines são os verdadeiros trabalhadores de dados. As operações em um Pipeline leem, modificam, enriquecem, limpam e gravam dados. A orquestração de Pipelines é feita por meio de outros Pipelines e/ou Workflows.

TRANSFORM
Uma Transformação é uma unidade de trabalho realizada em um Pipeline. Operações típicas de Transformação são leitura de dados de arquivos, bancos de dados, execução de pesquisas ou junções, enriquecimento, limpeza de dados e muito mais. Todas as transformações em um Pipeline são executadas em paralelo. Transformações processam dados e movem lotes de dados processados em Hops para processamento por Ações subsequentes.
WORKFLOW
Um Workflow é uma sequência de operações que são executadas sequencialmente por padrão (com execução paralela opcional). Os Workflows geralmente não operam nos dados diretamente, mas executam tarefas de orquestração. Tarefas típicas em um Workflow consistem em recuperar e arquivar dados, enviar e-mails, lidar com erros etc. )

PROJETOS E AMBIENTES
Projeto
Projetos Hop são um agrupamento conceitual de configurações, variáveis, objetos de metadados e fluxos de trabalho e pipelines. Projetos podem herdar metadados de projetos pais. Um projeto contém um ou mais ambientes onde a configuração real é definida.Exemplo: um projeto 'Sales' contém uma conexão de banco de dados 'customers' e vários fluxos de trabalho e pipelines. As configurações de tempo de execução, propriedades de conexão de banco de dados etc. são definidas nos ambientes 'dev', 'uat' e 'prd'.
Ambiente
Hop Environments são instâncias de projetos que mantêm as configurações de tempo de execução reais e outros objetos de metadados para um projeto.Exemplo: o ambiente 'dev' para o projeto 'Sales' especifica a leitura do host '10.0.0.1' para a conexão de banco de dados 'customers'

Objetivo do Projeto:
Carregar quatro bancos de dados diferentes, executar a filtragem necessária e, posteriormente, mesclar as tabelas: Sales, Client, Product, Brand. No final, salvar em um arquivo de vendas final.
A transformação Merge Join realiza uma mesclagem clássica entre conjuntos de dados com dados vindos de duas transformações de entrada diferentes. Essa transformação pressupõe que seus dados estão classificados nas chaves de junção.
Use as transformações Sort Rows nos fluxos de entrada para impor a classificação, se necessário. As opções de junção incluem INNER, LEFT OUTER, RIGHT OUTER e FULL OUTER.
Carregando as tabelas, Classificando os valores:

A transformação Sorted Merge mescla linhas provenientes de múltiplas transformações de entrada, desde que essas linhas sejam classificadas nos campos-chave fornecidos.
Executando a primeira fusão entre Vendas e Cliente:
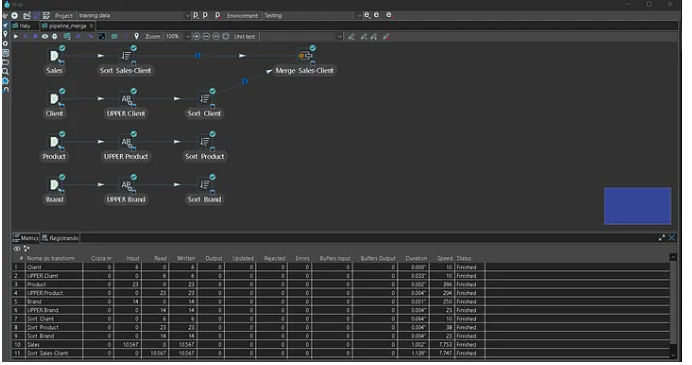
A transformação Sincronizar após mesclagem pode ser usada em conjunto com a transformação de pipeline Mesclar linhas (Diff) para inserir/atualizar/excluir campos do banco de dados com base na saída Mesclar linhas (Diff).
A transformação de pipeline Mesclar linhas (diff) anexa uma coluna Sinalizador a cada linha, com um valor de "idêntico", "alterado", "novo" ou "excluído". Essa coluna de sinalizador é então usada pela transformação de pipeline Sincronizar após mesclagem para executar atualizações/inserções/exclusões em uma tabela de conexão.
Finalizando com as fusões entre Vendas e Produto, e fusão entre Vendas e Marca, e no final salvando em um arquivo .txt em um diretório local.

Conclusão:
Apache Hop é uma ferramenta poderosa e versátil para integração de dados, que se destaca pela sua capacidade de facilitar o desenvolvimento, a execução e a gestão de pipelines de dados. Sua interface amigável e baseada em fluxo de trabalho permite que usuários, independentemente de seu nível de experiência, criem e gerenciem processos complexos de ETL (Extração, Transformação e Carga) de forma intuitiva.
Além disso, a flexibilidade do Apache Hop em suportar diferentes fontes de dados e formatos proporciona uma solução robusta para organizações que buscam melhorar sua governança de dados e aumentar a eficiência de suas operações. A natureza open-source da ferramenta também fomenta uma comunidade ativa, que contribui para melhorias contínuas e inovação.
Em um cenário onde a agilidade e a precisão na manipulação de dados são cruciais, Apache Hop se posiciona como uma escolha estratégica para empresas que desejam otimizar seus processos de integração de dados, garantindo que possam extrair insights valiosos e tomar decisões informadas com base em dados de qualidade. Assim, a adoção do Apache Hop pode ser um passo significativo para qualquer organização que busque aprimorar sua infraestrutura de dados e suas capacidades analíticas.
Referências:
Site Oficial do Apache Hop
A fonte primária para documentação, downloads e tutoriais.
Documentação do Apache Hop
Instruções detalhadas sobre instalação, configuração e uso da ferramenta.
Blog do Apache Hop
Artigos e atualizações sobre novos recursos, casos de uso e melhores práticas.
Repositório GitHub do Apache Hop
Código-fonte e informações sobre contribuições da comunidade.



Comentários