
ETL com Apache Spark
- Luiz Henrique de Oliveira Bueno
- 28 de fev. de 2025
- 14 min de leitura

Introdução ao ETL e ao Apache Spark
Arquitetura do Apache Spark
Implementando ETL com Apache Spark (com exemplos de código)
Melhores práticas e desafios
O Apache Spark é Altamente Integrável com Outras Tecnologias
Conclusão e referências
Capítulo 1: Introdução ao ETL e ao Apache Spark
A crescente quantidade de dados gerados diariamente exige ferramentas eficientes para processamento e análise. Nesse contexto, o ETL (Extract, Transform, Load) desempenha um papel essencial ao permitir a extração, transformação e carregamento de dados de diferentes fontes para sistemas analíticos.
O Apache Spark surge como uma solução poderosa para esses processos, proporcionando alta performance e escalabilidade em grandes volumes de dados. Diferente das abordagens tradicionais baseadas em sistemas de banco de dados, o Spark permite o processamento distribuído, tornando-se uma escolha ideal para pipelines de ETL modernos.
Neste capítulo, exploraremos os conceitos fundamentais do ETL e como o Apache Spark se encaixa nesse cenário, possibilitando a manipulação eficiente de dados em larga escala.
O que é ETL?
ETL é um processo essencial em engenharia de dados, dividido em três fases principais:
Extração (Extract): Coleta de dados de diferentes fontes, como bancos de dados, APIs, arquivos CSV ou JSON.
Transformação (Transform): Processamento dos dados para padronização, limpeza e enriquecimento, tornando-os utilizáveis.
Carregamento (Load): Armazenamento dos dados transformados em um destino apropriado, como um data warehouse ou um banco de dados analítico.
Ao longo dos anos, novas tecnologias surgiram para otimizar o ETL, permitindo que ele seja realizado em tempo real ou em lote, dependendo das necessidades do sistema.
Por que usar Apache Spark para ETL?
O Apache Spark é uma estrutura de processamento distribuído que oferece diversas vantagens para a implementação de ETL, como:
Alta velocidade: Utiliza processamento na memória, reduzindo a necessidade de leituras e gravações em disco.
Escalabilidade: Funciona em clusters distribuídos, permitindo o processamento eficiente de grandes volumes de dados.
Flexibilidade: Suporta múltiplas fontes de dados e diversas linguagens, como Python (PySpark), Scala e Java.
Processamento em tempo real: Com o Spark Streaming, é possível construir pipelines de ETL em tempo real.
Exploraremos como essas características tornam o Spark uma ferramenta essencial para engenharia de dados e como ele pode ser utilizado para construir pipelines ETL eficientes.
Capítulo 2: Arquitetura do Apache Spark

O Apache Spark é uma plataforma de processamento distribuído amplamente utilizada para análise de dados em larga escala. Sua arquitetura foi projetada para oferecer alta performance, escalabilidade e flexibilidade, permitindo que os desenvolvedores criem pipelines de ETL (Extract, Transform, Load) eficientes e integráveis a diversas fontes de dados.
Neste capítulo, exploraremos os principais componentes do Spark, seus diferentes modos de execução e como ele gerencia o processamento distribuído.
Visão Geral da Arquitetura
A arquitetura do Apache Spark segue o modelo Master-Slave, dividindo as responsabilidades entre diferentes componentes. O Driver Program coordena o processamento, enquanto os Executors executam as tarefas em um cluster distribuído.
A seguir, apresentamos os principais componentes do Spark:
1. Driver Program
O Driver Program é a aplicação principal do Spark, responsável por iniciar a execução do código e coordenar a distribuição das tarefas entre os nós do cluster. Ele desempenha as seguintes funções:
Criação do SparkContext, que gerencia a comunicação com o cluster.
Definição da lógica de processamento e distribuição das tarefas.
Coleta e agregação dos resultados processados pelos executors.
2. Cluster Manager
O Cluster Manager gerencia os recursos computacionais do ambiente distribuído. O Spark pode ser executado em diferentes tipos de gerenciadores de cluster:
Standalone: Gerenciador nativo do Spark, ideal para testes e pequenos clusters.
YARN (Yet Another Resource Negotiator): Usado em ambientes Hadoop, permitindo integração com outras ferramentas do ecossistema Big Data.
Mesos: Um gerenciador de cluster mais genérico, que pode executar múltiplas aplicações distribuídas.
Kubernetes: Permite executar o Spark em contêineres Docker, facilitando a escalabilidade e a orquestração.
3. Executors
Os Executors são os processos responsáveis por executar as tarefas atribuídas pelo Driver. Cada executor roda em um nó do cluster e possui memória e CPU alocadas para processar os dados de maneira distribuída.
Os executors desempenham dois papéis fundamentais:
Execução das Tarefas: Cada executor recebe uma parte dos dados e executa a operação designada.
Armazenamento em Cache: Dados intermediários podem ser armazenados em memória para reduzir latências.
4. RDDs, DataFrames e Datasets
O Spark oferece diferentes abstrações para manipulação de dados distribuídos, cada uma com características específicas:
RDD (Resilient Distributed Dataset):
Estrutura básica do Spark para processamento distribuído.
Imutável, tolerante a falhas e distribuída automaticamente.
Operações podem ser transformações (como map, filter) ou ações (como collect, count).
DataFrame:
Estrutura tabular semelhante a uma tabela SQL.
Mais eficiente que RDDs, pois otimiza consultas usando o Catalyst Optimizer.
Suporte a múltiplas linguagens, incluindo Python, Scala e Java.
Dataset:
Abstração semelhante ao DataFrame, mas com suporte a tipos fortemente tipados em Scala e Java.
Oferece melhor segurança em tempo de compilação, reduzindo erros.
5. O Motor de Execução do Spark
O Spark é baseado em um modelo de processamento distribuído chamado Directed Acyclic Graph (DAG). Esse modelo permite que o Spark otimize a execução de tarefas, minimizando leituras e gravações desnecessárias em disco.
O processo de execução segue as seguintes etapas:
Criação do RDD ou DataFrame.
Aplicação de transformações, gerando um DAG de execução.
Envio do DAG para o Driver, que divide em estágios.
Distribuição das tarefas entre os executors.
Execução das tarefas e armazenamento dos resultados.
6. Modos de Execução do Spark
O Spark pode ser executado em diferentes configurações, dependendo do ambiente e da necessidade de escalabilidade:
Modo Local:
Execução em uma única máquina, útil para testes e desenvolvimento.
Nenhuma configuração de cluster necessária.
Modo Cluster:
Distribui a carga de trabalho entre múltiplos nós, essencial para o processamento de grandes volumes de dados.
Pode utilizar gerenciadores como YARN, Mesos ou Kubernetes.
Modo Cliente (Client Mode):
O Driver roda na máquina do usuário e os executors no cluster.
Indicado para aplicações interativas.
Modo Cluster (Cluster Mode):
O Driver é executado em um nó do cluster, melhorando a resiliência.
Indicado para aplicações de produção.
Exemplo de Código: Criando um DataFrame no Spark
Agora que entendemos a arquitetura do Spark, vejamos um exemplo de código simples que cria um DataFrame a partir de um arquivo CSV:
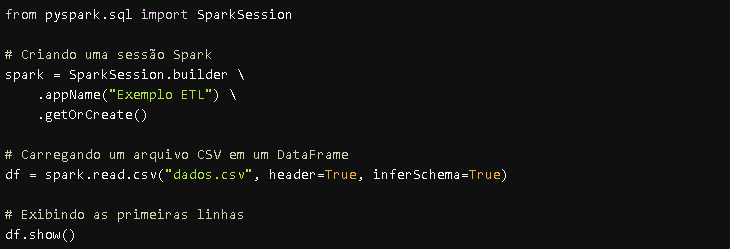
Esse exemplo demonstra como o Apache Spark pode ser utilizado para carregar e visualizar dados de forma eficiente.
A arquitetura do Spark foi projetada para oferecer alto desempenho em ambientes distribuídos, tornando-o uma escolha ideal para pipelines de ETL. Com componentes como RDDs, DataFrames, Executors e Cluster Managers, o Spark permite o processamento eficiente de grandes volumes de dados, garantindo escalabilidade e flexibilidade.
No próximo capítulo, exploraremos a implementação prática de um pipeline ETL com Apache Spark, incluindo extração, transformação e armazenamento dos dados.
Capítulo 3: Implementando ETL com Apache Spark

A implementação de um pipeline ETL (Extract, Transform, Load) com Apache Spark permite processar grandes volumes de dados de forma eficiente e distribuída. Utilizando PySpark, a API Python do Apache Spark, conseguimos manipular dados de diferentes fontes, aplicar transformações avançadas e armazená-los em diversos formatos e sistemas.
Neste capítulo, exploraremos cada fase do ETL com exemplos detalhados e boas práticas.
1. Extração de Dados (Extract)
A primeira etapa envolve a coleta de dados de diversas fontes, como bancos de dados, arquivos CSV, JSON, Parquet ou APIs. O Spark oferece conectores nativos para diversas tecnologias, facilitando a extração e garantindo escalabilidade.
1.1 Extraindo dados de arquivos estruturados
O Spark permite carregar arquivos CSV, JSON e Parquet de maneira simples:

1.2 Extraindo dados de um banco de dados relacional
O Spark pode se conectar a bancos de dados relacionais, como MySQL, PostgreSQL e SQL Server, utilizando JDBC:

1.3 Extraindo dados de uma API
O Spark pode interagir com APIs externas usando bibliotecas como requests para coletar dados e convertê-los em um DataFrame:

2. Transformação dos Dados (Transform)
A etapa de transformação envolve limpeza, agregação, filtragem, enriquecimento e padronização dos dados. O Spark permite aplicar diversas operações de forma distribuída.
2.1 Limpeza de Dados
Removendo valores nulos e duplicados:
df_clean = df_csv.dropna().dropDuplicates()
2.2 Agregação e Estatísticas
Agrupando dados e calculando métricas:
df_agg = df_transformed.groupBy("categoria").agg({"salario": "avg", "idade": "max"})
df_agg.show()
2.3 Junção de Dados
O Spark permite unir dados de diferentes fontes usando joins:
df2 = spark.read.csv("outros_dados.csv", header=True, inferSchema=True)
df_joined = df_transformed.join(df2, "id", "inner")
df_joined.show()
2.4 Transformação de Estruturas de Dados
Convertendo um DataFrame para um formato estruturado:

3. Carregamento dos Dados (Load)
Após a transformação, os dados são armazenados em formatos apropriados para consumo posterior. O Spark suporta diversos destinos, como bancos de dados, sistemas distribuídos e arquivos locais.
3.1 Salvando em Banco de Dados

3.2 Salvando em Arquivos Estruturados

3.3 Salvando em um Data Lake (HDFS ou S3)

Ou diretamente no Amazon S3:

4. Pipeline ETL Completo
Aqui está um exemplo completo de um pipeline ETL utilizando Spark:
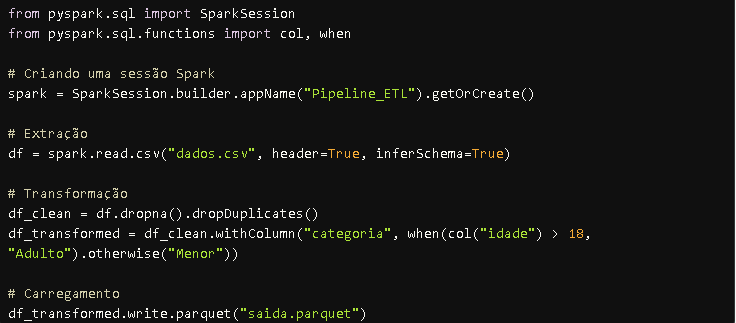
Esse pipeline pode ser facilmente escalado para processar grandes volumes de dados distribuídos em clusters
A implementação de um ETL com Apache Spark exige um entendimento claro de suas três etapas principais:
✅ Extração: Coletar dados de diferentes fontes.
✅ Transformação: Limpar, padronizar e enriquecer os dados.
✅ Carregamento: Armazenar os dados transformados em um formato otimizado.
O Apache Spark oferece alta performance e escalabilidade para pipelines de dados, tornando-se uma das principais ferramentas para processamento distribuído.
No próximo capítulo, exploraremos melhores práticas e desafios ao trabalhar com ETL no Apache Spark, garantindo otimização e eficiência nos processos.
Capítulo 4: Melhores Práticas e Desafios no ETL com Apache Spark

A criação de pipelines ETL (Extract, Transform, Load) eficientes com Apache Spark exige não apenas conhecimento da ferramenta, mas também a aplicação de boas práticas para evitar problemas de desempenho, consumo excessivo de memória e falhas de execução.
Neste capítulo, aprofundamos essas estratégias e discutimos desafios comuns enfrentados ao usar o Spark para ETL.
1. Boas Práticas para ETL com Apache Spark
1.1. Escolher a Abstração Certa: DataFrames vs. RDDs
O uso de RDDs (Resilient Distributed Datasets) no Spark é menos eficiente que DataFrames e Datasets, pois RDDs não possuem otimizações internas.
✅ Recomendado:
df = spark.read.csv("dados.csv", header=True, inferSchema=True)
🚫 Evite:
rdd = spark.sparkContext.textFile("dados.csv")
Benefícios dos DataFrames:
Melhor otimização pelo Catalyst Optimizer.
Suporte a operações SQL.
Melhor gerenciamento de memória.
1.2. Cache e Persistência Estratégica
Se um DataFrame for usado várias vezes, armazená-lo em cache evita recomputações.
df.cache()
df.show()
Para operações mais complexas, pode-se usar persist() com diferentes níveis de armazenamento:
df.persist(storageLevel="MEMORY_AND_DISK")
1.3. Uso Inteligente de Particionamento
O particionamento correto melhora a distribuição das tarefas no cluster e reduz o tráfego de dados entre nós.
df = df.repartition(10, "coluna_chave")
Se o DataFrame já estiver excessivamente particionado, reduzir as partições pode melhorar a performance:
df = df.coalesce(4)
1.4. Escolher Formatos de Arquivo Eficientes
O formato CSV consome mais espaço e processamento. O Parquet é um formato colunar otimizado para o Spark.
df.write.parquet("saida.parquet")
Parquet oferece:
✅ Melhor compressão.
✅ Leitura mais eficiente de colunas específicas.
✅ Melhor integração com ferramentas analíticas.
1.5. Configuração Otimizada do Cluster
Ajuste de configurações do Spark para evitar gargalos de processamento:

2. Desafios Comuns e Como Resolver
2.1. Gerenciamento de Memória Insuficiente
❌ Problema: O Spark consome muita memória e pode falhar com OutOfMemoryError.
✅ Solução:
Aumentar a memória dos executores (spark.executor.memory).
Utilizar persist(DISK_ONLY) para evitar consumo excessivo de RAM.
Reduzir o número de partições (coalesce(n)).
2.2. Shuffles Excessivos
❌ Problema: Operações como groupBy(), join() e sort() geram movimentação excessiva de dados entre nós.
✅ Solução:
Utilizar colunas particionadas para evitar movimentação de dados desnecessária.
Aplicar broadcast join para conjuntos de dados menores:
from pyspark.sql.functions import broadcast
df_result = df_large.join(broadcast(df_small), "id")
2.3. Lentidão no Carregamento de Dados
❌ Problema: Arquivos CSV podem ser lidos lentamente devido à falta de indexação e compressão.
✅ Solução:
Converter os dados para Parquet para melhor eficiência.
Utilizar Apache Arrow para transferir dados entre Pandas e Spark:
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
2.4. Manutenção de Pipelines em Produção
❌ Problema: Falta de monitoramento e logging adequado dificulta a depuração de falhas.
✅ Solução:
Utilizar ferramentas como Apache Airflow para orquestrar ETLs.
Implementar logging com log4j.properties.
Monitorar métricas com Spark UI e Ganglia.
3. Estratégias Avançadas para Melhorar a Performance
3.1. Uso de Colunas em vez de Linhas
O Spark é mais eficiente ao processar colunas do que linhas.
✅ Exemplo correto:
df.select("coluna1", "coluna2").show()
🚫 Evite:
for row in df.collect():
print(row)
3.2. Uso de Window Functions para Agregações Eficientes
Ao invés de groupBy(), que pode causar shuffles, Window Functions permitem cálculos eficientes.
📝 Exemplo: Calculando a média de salário por departamento sem groupBy:

3.3. Configuração de Auto Broadcast Join Threshold
Se um DataFrame pequeno for usado em um join, o Spark pode fazer broadcast automático para acelerar o processamento.
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "50MB")
4. Ferramentas Complementares para ETL no Spark
Além do Spark, outras ferramentas podem ajudar a gerenciar e otimizar pipelines ETL:

A otimização de pipelines ETL com Spark envolve:
✅ Escolher a abstração correta (DataFrames em vez de RDDs).
✅ Gerenciar memória com cache e persistência estratégica.
✅ Evitar shuffles desnecessários e usar partições eficientes.
✅ Utilizar formatos como Parquet para maior eficiência.
✅ Implementar monitoramento e logging para produção.
No próximo capítulo, faremos um resumo dos principais conceitos abordados e apresentaremos fontes para aprofundamento no tema.
Capítulo 5: O Apache Spark é Altamente Integrável com Outras Tecnologias

O Apache Spark se tornou uma ferramenta essencial no processamento de dados em larga escala devido à sua capacidade de integração com diversas tecnologias. Seja para armazenamento, orquestração, processamento em tempo real ou machine learning, o Spark pode ser combinado com diferentes sistemas para criar soluções robustas e escaláveis.
Neste capítulo, exploramos as principais integrações do Spark e como elas podem ser utilizadas para melhorar o desempenho e a flexibilidade dos pipelines de dados.
1. Integração com Sistemas de Armazenamento
O Apache Spark pode ler e gravar dados em diversos sistemas de armazenamento, desde bancos de dados relacionais até soluções distribuídas para Big Data.
1.1. Bancos de Dados Relacionais (MySQL, PostgreSQL, SQL Server)
O Spark suporta JDBC (Java Database Connectivity), permitindo a leitura e escrita de dados em bancos relacionais.
✅ Exemplo: Carregando dados de um banco MySQL

1.2. Data Lakes e Armazenamento Distribuído (HDFS, Amazon S3, Google Cloud Storage)
O Spark pode processar dados diretamente de sistemas distribuídos como HDFS (Hadoop Distributed File System) e serviços de nuvem como AWS S3 e Google Cloud Storage.
✅ Exemplo: Gravando um DataFrame no HDFS
df.write.parquet("hdfs://namenode:9000/datalake/saida.parquet")
✅ Exemplo: Lendo dados do Amazon S3
df = spark.read.parquet("s3://meu-bucket/dados/")
1.3. Apache Hive
O Spark pode ser integrado ao Apache Hive, permitindo consultas SQL em grandes volumes de dados armazenados em HDFS.
✅ Exemplo: Lendo uma tabela Hive com Spark SQL
df = spark.sql("SELECT * FROM banco_dados.tabela")
2. Integração com Ferramentas de Orquestração
O Spark pode ser integrado a ferramentas que automatizam e gerenciam workflows de dados.
2.1. Apache Airflow
O Apache Airflow é amplamente utilizado para orquestrar pipelines de dados, permitindo agendar e monitorar execuções do Spark.
✅ Exemplo: Criando um DAG no Airflow para rodar um Spark Job

2.2. Kubernetes
O Spark pode ser executado em Kubernetes, permitindo escalabilidade automática e gerenciamento eficiente de recursos.
✅ Exemplo: Submetendo um Spark Job no Kubernetes

3. Integração com Processamento em Tempo Real
Além do processamento em lote (batch), o Spark pode ser utilizado para streaming de dados em tempo real.
3.1. Apache Kafka
O Apache Kafka é um dos principais sistemas de mensageria para streaming de dados. O Spark pode consumir dados do Kafka e processá-los em tempo real.
✅ Exemplo: Lendo dados do Kafka com Spark Streaming

3.2. Apache Flink
Embora o Spark Streaming seja eficiente, o Apache Flink é outra ferramenta popular para processar eventos em tempo real. Muitos ambientes utilizam Flink e Spark juntos, combinando o melhor de cada tecnologia.
4. Integração com Machine Learning e Inteligência Artificial
O Spark possui uma biblioteca nativa para Machine Learning, chamada MLlib, mas também pode ser integrado a outras ferramentas populares para IA.
4.1. Spark MLlib
O MLlib oferece algoritmos de aprendizado de máquina escaláveis para análise de dados em larga escala.
✅ Exemplo: Criando um modelo de regressão linear com Spark MLlib

4.2. TensorFlow e PyTorch
Para modelos mais complexos, como redes neurais profundas, o Spark pode ser integrado ao TensorFlow ou PyTorch.
✅ Exemplo: Usando TensorFlow com Spark

5. Integração com Ferramentas de Visualização de Dados
Após processar os dados com Spark, é comum integrá-lo a ferramentas de BI para análise e visualização.
5.1. Apache Superset
O Apache Superset é uma ferramenta de BI open-source que pode se conectar ao Spark via Presto ou Trino.
5.2. Tableau e Power BI
Ferramentas como Tableau e Power BI podem consumir dados do Spark usando conectores JDBC.
✅ Exemplo: Conectando Power BI ao Spark via JDBC
jdbc:spark://servidor_spark:10000/default
O Apache Spark não é uma solução isolada, mas sim uma ferramenta altamente integrável com diversas tecnologias. Suas conexões com bancos de dados, sistemas de armazenamento distribuído, processamento em tempo real e machine learning permitem criar pipelines de dados robustos e escaláveis.
Agora que exploramos essas integrações, os próximos passos envolvem experimentação prática, conectando o Spark a diferentes ferramentas para aprimorar suas capacidades analíticas e operacionais.
Conclusão
O Apache Spark se consolidou como uma das ferramentas mais eficientes para o processamento de dados distribuído, oferecendo escalabilidade, velocidade e flexibilidade para lidar com grandes volumes de informações. Neste livro, exploramos sua arquitetura, implementação prática e as estratégias para otimizar a execução de pipelines ETL (Extract, Transform, Load).
Ao longo dos capítulos, discutimos como o Spark se diferencia de outras ferramentas, sua estrutura baseada em RDDs, DataFrames e Datasets, e como esses elementos se combinam para oferecer um processamento de alto desempenho. Além disso, abordamos a importância da configuração adequada do ambiente, o uso eficiente da memória e técnicas para evitar operações custosas, como shuffles excessivos e joins ineficientes.
Outro ponto essencial foi a implementação de pipelines ETL completos com Spark, desde a extração de dados de diferentes fontes até sua transformação e armazenamento otimizado em formatos como Parquet e sistemas distribuídos como HDFS e AWS S3. Exploramos estratégias para particionamento, caching e persistência, demonstrando como essas técnicas podem impactar significativamente a performance de um pipeline de dados.
Também discutimos os desafios comuns enfrentados na utilização do Spark, incluindo gerenciamento de memória, tuning de parâmetros e monitoramento de jobs em produção. A adoção de ferramentas complementares, como Apache Airflow para orquestração de workflows e Apache Kafka para processamento em tempo real, mostrou-se essencial para a construção de soluções robustas e escaláveis.
Além disso, vimos como o Spark se integra com bancos de dados relacionais, sistemas de mensageria, plataformas de machine learning e ferramentas de visualização de dados, permitindo que ele seja utilizado em diversas aplicações, desde análise preditiva até processamento contínuo de eventos.
O Que Vem a Seguir?
A aprendizagem do Apache Spark não termina aqui. Para aprofundar seus conhecimentos e consolidar as habilidades adquiridas, é recomendável explorar projetos práticos, testar diferentes configurações de cluster e experimentar novas aplicações do Spark em cenários reais. Criar pipelines próprios, testar Spark Streaming para análise de dados em tempo real e integrar o Spark com frameworks de inteligência artificial são alguns dos próximos passos possíveis.
A melhor maneira de avançar é se conectar à comunidade, explorar documentações oficiais, participar de fóruns e contribuir para projetos open-source. Aprender com desafios práticos e interagir com profissionais experientes pode acelerar o domínio da tecnologia e abrir novas oportunidades no mercado de Big Data e Machine Learning.
O crescimento exponencial do volume de dados torna o Apache Spark uma ferramenta cada vez mais relevante. Seu domínio pode ser um diferencial competitivo para engenheiros de dados, cientistas de dados e desenvolvedores que buscam trabalhar com análises avançadas, processamento distribuído e inteligência artificial em larga escala.
Até aqui tivemos uma base sólida para entender como o Spark pode ser utilizado para criar pipelines ETL eficientes, otimizar o processamento de dados e integrar-se a diferentes tecnologias. O próximo passo é aplicar esse conhecimento na prática e explorar o vasto universo do processamento distribuído.
A jornada com Apache Spark não é apenas sobre tecnologia, mas sobre a capacidade de transformar dados brutos em insights valiosos e decisões estratégicas. O conhecimento adquirido aqui pode ser o ponto de partida para projetos inovadores e soluções de alto impacto.
Referências e Links Úteis
1. Documentação Oficial
A documentação oficial do Apache Spark é o melhor recurso para entender suas funcionalidades, configurações e APIs.
📌 Apache Spark (Documentação Oficial)🔗 https://spark.apache.org/docs/latest/
📌 PySpark API Reference🔗 https://spark.apache.org/docs/latest/api/python/
📌 Spark SQL, DataFrames e Datasets🔗 https://spark.apache.org/docs/latest/sql-programming-guide.html
2. Livros Recomendados
📌 High Performance Spark – Holden Karau & Rachel Warren🔗 https://www.oreilly.com/library/view/high-performance-spark/9781491943199/
📌 Spark: The Definitive Guide – Bill Chambers & Matei Zaharia🔗 https://www.oreilly.com/library/view/spark-the-definitive/9781491912201/
📌 Learning Spark: Lightning-Fast Big Data Analysis – Jules S. Damji, Brooke Wenig, Tathagata Das, Denny Lee🔗 https://www.oreilly.com/library/view/learning-spark-2nd/9781492050032/
3. Cursos Online
Coursera
📌 Big Data Analysis with Spark – University of California San Diego🔗 https://www.coursera.org/learn/big-data-analysis-spark
📌 Data Science with Databricks and Apache Spark – Databricks🔗 https://www.coursera.org/learn/data-science-with-databricks-spark
Udacity
📌 Data Engineering with Apache Spark🔗 https://www.udacity.com/course/data-engineering-with-apache-spark--ud2002
Databricks Academy
📌 Apache Spark Fundamentals🔗 https://www.databricks.com/learn/training
4. Repositórios e Tutoriais no GitHub
📌 Apache Spark (Código-fonte oficial)🔗 https://github.com/apache/spark
📌 Exemplos de ETL com PySpark🔗 https://github.com/databricks/LearningSparkV2
📌 Projetos Open-Source relacionados ao Spark🔗 https://github.com/topics/apache-spark
5. Ferramentas e Frameworks Relacionados
📌 Apache Airflow (Orquestração de Workflows de ETL)🔗 https://airflow.apache.org/
📌 Apache Kafka (Streaming de Dados em Tempo Real)🔗 https://kafka.apache.org/
📌 Delta Lake (Armazenamento Otimizado para Spark)🔗 https://delta.io/
📌 MLflow (Gerenciamento de Modelos de Machine Learning com Spark)🔗 https://mlflow.org/
📌 Presto (Consultas Distribuídas para Dados em Spark e Hadoop)🔗 https://prestodb.io/



Comentários